
Big Data Lakehouse Architecture: Integrating the Scalability of Data Lakes with the Structure of Data Warehouses
Imagine two rivers flowing side by side — one wild, unrestrained, carrying everything from fine grains to large rocks; the other calm, channelled, and clear, designed for easy navigation. These rivers represent two major data management paradigms: data lakes and data warehouses. For years, organisations chose one over the other — flexibility versus structure. But what if both could merge into a single, powerful stream? That’s the promise of the Data Lakehouse architecture — an innovation that blends the best of both worlds.
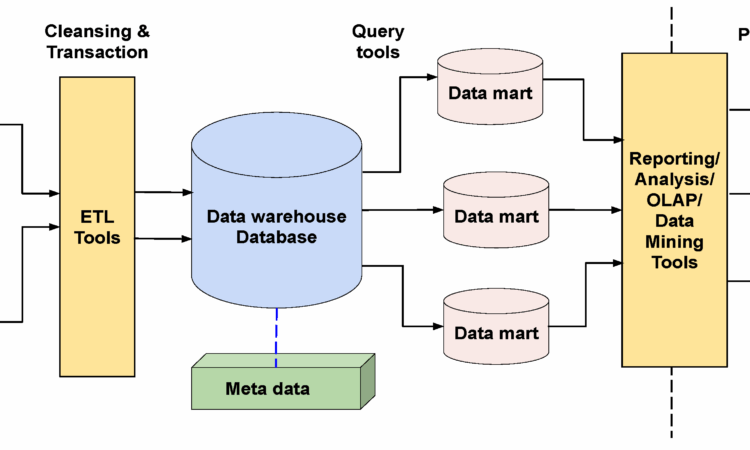
Data lakehouses combine the scalability and low-cost storage of data lakes with the governance, schema, and performance of data warehouses. They are becoming the backbone of modern analytics and business intelligence systems.
The Evolution from Lakes and Warehouses
In the early days of big data, organisations stored raw information in data warehouses — systems optimised for structured, query-ready data. While these were excellent for reporting, they struggled with the explosion of unstructured data from sensors, social media, and IoT devices.
Then came data lakes, offering a vast, low-cost repository for every kind of data — structured, semi-structured, or unstructured. They allowed flexibility but often lacked the order and consistency analysts needed.
The Data Lakehouse emerged to bridge this divide, merging the governance and performance of warehouses with the adaptability of lakes. Learners exploring advanced data ecosystems through a business analyst course in Pune often study how this hybrid architecture reshapes enterprise decision-making.
Core Principles of a Lakehouse
At its core, a lakehouse allows both data engineers and analysts to work from a unified platform. Instead of duplicating data between systems, it provides a single source of truth — where data can be stored in its raw form but also structured when needed.
The architecture typically includes:
- Unified storage layer (often built on cloud object stores like S3 or Azure Data Lake)
- Transactional consistency, ensuring ACID compliance across massive datasets
- Open formats such as Parquet or Delta Lake for interoperability
- Integrated governance and security, allowing better compliance and access control
This unification means teams no longer waste time synchronising two different environments. They can now build machine learning models, dashboards, and reports — all from the same data foundation.
Why the Lakehouse Matters
Businesses today demand speed, accuracy, and flexibility. Waiting days for data pipelines to move from lakes to warehouses slows decision-making. The lakehouse eliminates this friction.
Data scientists can access raw data for experimentation, while business analysts can query clean datasets simultaneously. This collaboration reduces latency and increases reliability.
Moreover, companies save costs by avoiding data duplication and maintaining a single storage system. These efficiencies are why top enterprises — from e-commerce giants to healthcare innovators — are moving toward lakehouse architectures.
How It Empowers Analysts and Decision-Makers
In a traditional setup, analysts often depend on IT teams to prepare and clean datasets before any analysis can begin. With lakehouses, this dependency reduces dramatically. Analysts can directly interact with real-time data streams, perform ad-hoc analysis, and generate insights faster.
Professionals trained through structured programmes like a business analyst course in Pune learn how to design dashboards, develop SQL-based queries on data lakehouse platforms, and interpret patterns that drive business growth. This shift empowers analysts to move from passive consumers of data to active decision-makers.
Challenges in Implementation
While promising, building a lakehouse isn’t without hurdles. Integrating streaming and batch data pipelines requires significant architectural design. Data governance must evolve to maintain security and compliance in such open systems.
There’s also a cultural shift involved — encouraging teams accustomed to separate warehouses and lakes to collaborate on shared infrastructure. Tools like Delta Lake, Apache Iceberg, and Hudi have emerged to ease this transition, providing robust data versioning and consistency across diverse workloads.
Conclusion
The Data Lakehouse isn’t just a technical upgrade — it’s a strategic transformation. It breaks down silos, empowers teams, and ensures that decision-making is faster and more data-driven.
By merging flexibility with structure, organisations can finally manage their data as both a creative and analytical resource. For analysts and business professionals alike, mastering this hybrid model is essential to staying competitive in the digital age.
Just as a river system thrives when its tributaries flow in harmony, enterprises flourish when structured and unstructured data come together — creating a seamless, intelligent stream of insight.




{kind=link}